
티스토리 뷰
스레드풀을 사용하면서 생긴 궁금증을 정리해보려 합니다.
Thread는 Runnable 객체만 실행할 수 있는데, ExecutorService(스레드 풀)는 어떻게 Callable 객체도 실행할 수 있을까?
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}ExecutorService에서 Callable 객체를 submit하면, 먼저 해당 Callable 객체는 RunnableFuture로 감싸집니다.
public interface RunnableFuture<V> extends Runnable, Future<V> {
void run();
}
public class FutureTask<V> implements RunnableFuture<V> {
private Callable<V> callable;
private Object outcome;
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
}
public void run() {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
result = c.call();
outcome = result;
}
}
private V get() throws ExecutionException {
Object x = outcome;
return (V)x;
}
}
RunnableFuture의 run() 메서드를 실행하면 내부적으로 원래의 Callable이 호출되어 결과 값을 생성하고, 이 값을 내부에 저장합니다. 이후 Future.get()을 호출하면, 앞서 저장된 결과 값을 반환받을 수 있습니다.
이러한 구조 덕분에 ExecutorService(스레드 풀)에서는 Thread와는 달리 Callable 객체도 사용할 수 있습니다.
Thread는 한 번 실행되면 TERMINATED 상태가 되어 다시 실행할 수 없는데, 스레드풀에서는 어떻게 재사용할 수 있을까?
일반적으로 스레드 풀은 직접 구현하기보다는 라이브러리를 통해 사용하는 경우가 많기 때문에, 내부 동작 방식은 쉽게 알기 어렵다.
스레드 풀을 설명할 때 흔히 “스레드를 미리 생성해 풀에 보관해 두었다가, 필요할 때 꺼내어 사용하고 다시 반납한다”고 표현하는데, 이 설명 속 “꺼내서 사용한다”, “반납한다”는 표현은 자연스럽게 위와 같은 궁금증을 유발한다.
내부적으로는 어떤 방식으로 구현되어 있을까?
public class ThreadPoolExecutor extends AbstractExecutorService {
private final BlockingQueue<Runnable> workQueue;
private final HashSet<Worker> workers = new HashSet<>();
public void execute(Runnable command) {
...
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
...
}
private boolean addWorker(Runnable firstTask, boolean core) {
...
Worker w = new Worker(firstTask);
final Thread t = w.thread;
workers.add(w);
t.start();
...
}
}먼저, 스레드 풀은 스레드를 Worker 형태로 저장하며, 인스턴스를 생성할 때 바로 스레드를 생성하지 않습니다. 대신, execute 메서드가 호출되면 addWorker를 통해 스레드를 생성합니다.
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
final Thread thread;
Runnable firstTask;
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Runnable task = w.firstTask;
w.firstTask = null;
while (task != null || (task = getTask()) != null) {
...
task.run();
...
}
}
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
생성된 스레드(Worker)는 처음에는 firstTask를 수행한 후, 이후에는 무한 루프를 돌며 getTask()를 호출합니다.
이때 작업(Task)이 BlockingQueue 내부에 존재하지 않으면, workQueue.take()에 의해 스레드는 대기(wating) 상태가 되며, 새로운 작업이 큐에 들어오면 다시 실행(running) 상태로 전환되어 무한 루프를 계속 수행합니다.
종료 시에는 getTask()가 null을 반환하게 되어, 무한 루프가 종료되고 스레드도 함께 종료됩니다.
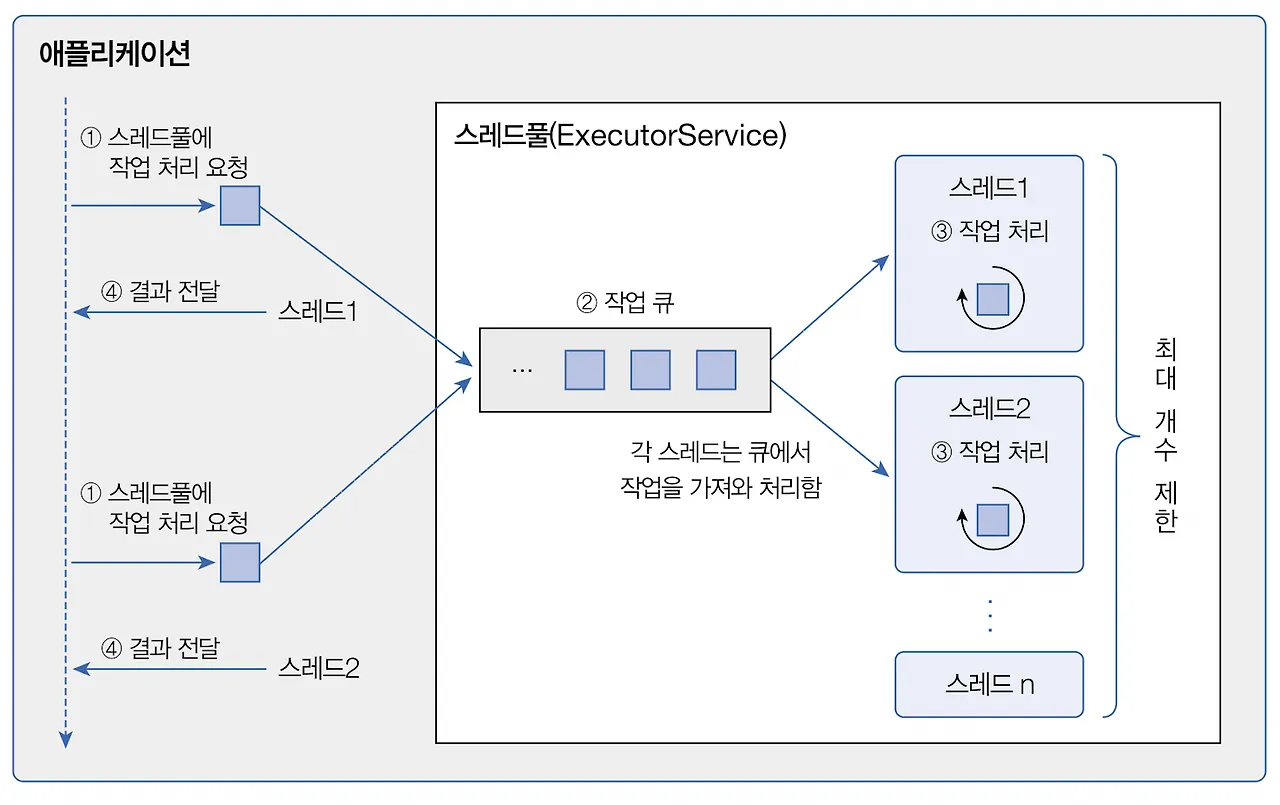
즉 스레드를 꺼내어 사용하고 다시 반납하는것이 아닌 스레드는 생성후 무한루프를 돌면서 작업을 대기하는 형태 입니다.
그렇기 때문에 스레드풀에 스레드는 TERMINATED 되지 않고 Wating 과 Running 상태를 반복하게됩니다.
'spring' 카테고리의 다른 글
| Tworld 대기열은 어떤식으로 구현되어있을까? (0) | 2025.05.01 |
|---|---|
| Spring Scheduler 동작 방식 (0) | 2024.06.19 |
| 어댑터 패턴을 활용기 (0) | 2024.06.16 |
| ShedLock 도입기 (0) | 2024.04.11 |
| Spring Boot 로그에 바인딩 매개변수가 표시되지 문제 해결 (0) | 2023.10.24 |
- Total
- Today
- Yesterday
- FormProperty
- defer-datasource-initialization
- Attribute Converter
- User Scenario
- java 17
- WebFlux 의존성
- ServletContainerInitializer
- CreatedDate
- JPA SQL Injection
- @Converter
- Spring Boot 3
- feignClient
- @ElementCollection
- @FormProperty
- 구글 OpenID
- dto 위치
- HandlesTypes
- entity 검증
- org.springframework:spring-webflux
- HTTPInterface
- dto 검증
- 구글 소셜로그인
- 유저 스토리
- BasicBinder
- setDateFormat
- 레이어드 아키텍처
- ValidateException
- DispatcherServletInitializer
- CreationTimestamp
- 유저 시나리오
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |